开本地大模型的好处,核心就是一句话:数据完全由你掌控,且长期使用成本极低。
我用一个简单的对比表格,帮你快速看清它和云端API(如OpenAI、文心一言等)的核心差异:
| 维度 | 本地大模型 (自部署) | 云端API (调用服务) |
|---|---|---|
| 数据隐私 | 极高。所有数据、对话历史都在你自己的硬盘和内存里,绝对不上传。 | 取决于厂商。虽然加密,但数据需发送到云端,存在合规风险(尤其涉及商业机密)。 |
| 网络依赖 | 完全离线可用。断网也能用,适合内网环境、远程办公。 | 必须联网。网络波动会影响响应速度,甚至服务不可用。 |
| 长期成本 | 低。一次性投入硬件成本后,电费+维护,无后续API调用费。 | 持续计费。按Token(字数)收费,高频使用或处理长文本时费用可观。 |
| 定制与微调 | 自由度高。可以自行微调模型参数,完全适配你的专业领域或特殊需求。 | 有限定制。通常只能通过提供案例(Few-shot)来引导,无法深度修改模型本身。 |
| 技术门槛 | 较高。需要配置环境(显卡驱动、Python等)和优化推理速度。 | 极低。注册账号获取API Key即可调用,无需运维。 |
| 速度与性能 | 取决于硬件。显卡越好速度越快,且不受其他用户挤占排队影响。 | 受厂商限制。有速率限制(Rate Limit),高峰期可能排队延迟。 |
特别是龙虾,1000万的token,几个连续任务就消耗完了,根本没有做什么事情
结合你的配置,能获得什么?
只要拥有 4张P104 8GB显卡,就非常适合运行MoE(混合专家)架构的模型,比如Qwen3.6-35B-A3B。
部署完成后,你可以实现:
- 长文档处理:本地跑35B模型,在保证质量的同时,上下文窗口可以开得很大,不用担心API按Token计费的问题。
- 代码辅助:可以24小时不间断运行,不用再担心代码泄露风险,对程序员来说是很好的本地辅助工具。
- 多用户共享:4卡并行,可以同时为多个内部用户或服务提供推理,而不产生额外费用。
- 可以开RPC服务: 将局域网里面的闲置显卡都利用起来,多卡并联计算
- 商业模型做主模: 本地模型跑子任务,就可以节约token
我同时开启4张8G显卡,待机情况下每个卡只有7W,30多度
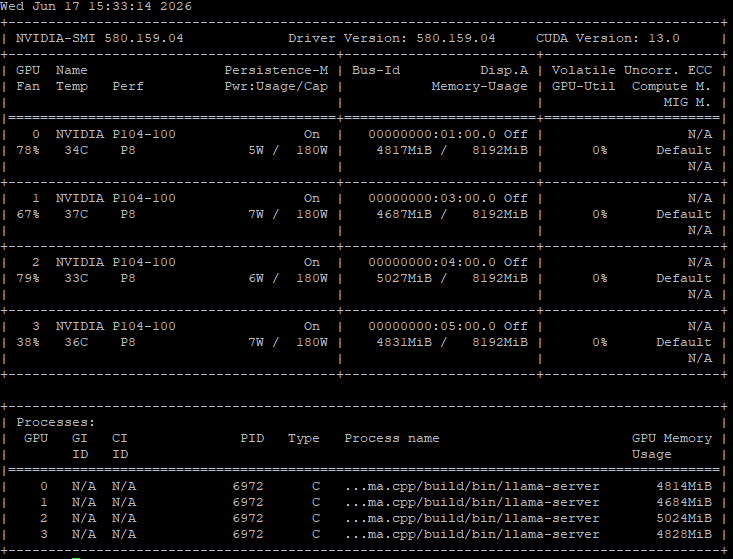
现在市面上P104显卡不足100元,买4张卡可以用到天荒地老,3080显卡1500以上要的吧?是P104的四倍。
但也有一些“麻烦事”需要注意
本地部署不是“即插即用”的,你需要面对:
- 硬件资源调度:你的P104是计算卡,需要确保主板供电和散热足够,同时要配置好CUDA环境。
- 软件堆栈维护:驱动、Python包、推理框架(如llama.cpp或vLLM)版本更新较快,有时新功能需要重新编译。
- 模型量化选择:你需要花时间测试不同量化等级(如IQ3_S、Q4_K_M),在速度和效果之间找到最适合你显卡的平衡点。
- Linux系统学习: 你需要学习linux服务器的相关知识
- 编程知识的学习: 解决不了的问题还需要编程解决
所以,本地部署适合哪些人
- 如果你对数据隐私非常敏感(如处理商业计划书、病历、内部代码),或者访问API不便(网络不稳定),那么部署本地大模型非常值得,几乎是“一劳永逸”的方案。
- 如果你是技术爱好者,享受搭建和调优的过程,这本身也是一个不错的学习项目。
当然了,本地模型速度肯定比不上商业模型,开龙虾或者爱马仕会慢,有一个办法就是使用我写的微型智能体
微型智能体速度快,少量的token就可以运行,功能相对于龙虾来说会弱,但是个人开发使用感觉还行,慢慢完善
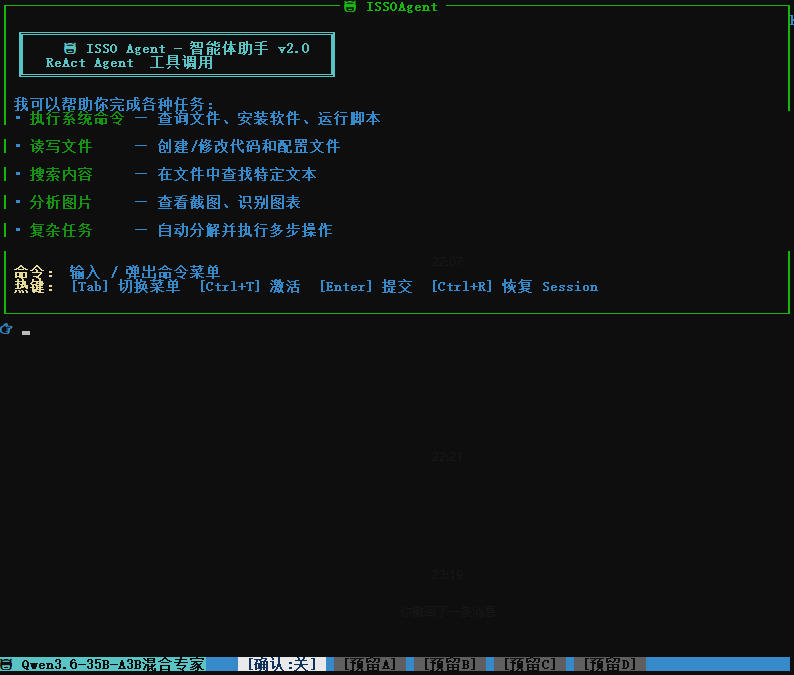
你也可以让小龙虾接入商业模型开发一个自己的agent
不要跟我说商业模型好,哪里白嫖的好,我们需要的是长期稳定无需管理的本地模型,后期不要维护不要去查今天为什么免费模型关了,商业模型更新了,充值用完了,地址失效了各种奇怪的问题,商业和本地配合着来,万一卡脖子了可以留个后手。
总的来说,如果有显卡硬件基础,已经具备了先决条件。唯一的挑战就是花些时间把软件环境跑通。一旦跑通,你就拥有了一个完全自主的“不花钱私人AI助手”。
要加ISSO AI兴趣小组的PM我

